Improving Data Quality in Insurance Quoting with AI
An agentic research assistant that turns a company name into reliable, structured data for live business insurance quoting
Overview
The brief was straightforward on the surface but demanding in practice. Build an API that accepts only a company name and country, and returns reliable, structured data to support business insurance quoting within a broker facing platform.
The system needed to identify the company’s official website, extract relevant company information such as business activity, size, and financial indicators, and deliver results quickly enough to be used in live quoting workflows. Both speed and data quality were critical, as the output directly influenced risk assessment, pricing, and eligibility decisions for products such as D&O.
Traditional approaches to this type of problem rely on rule based crawlers, rigid heuristics, and complex parsing logic. These systems are slow to adapt, difficult to maintain, and fragile when websites deviate from expected structures. The client was clear that they did not want a large or brittle codebase.
Approach
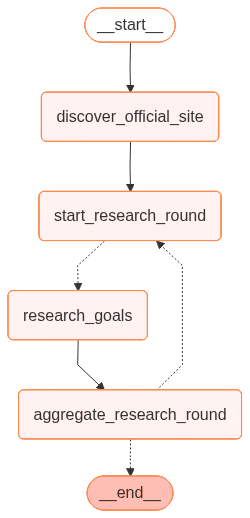
The system was designed as an agentic research service rather than a fixed crawler, with flexibility, speed, and reliability built in from the start. At its core was a small, generic execution engine that interpreted research goals provided at runtime, rather than hard coding behaviour into the system itself.
Research was organised as a dynamic graph of tasks, with multiple paths fanning out as needed based on what the system discovered. Relevant lines of enquiry could be pursued in parallel, while avoiding unnecessary work. Individual goals were executed asynchronously wherever possible, reducing overall response time and making the system suitable for live quoting workflows.
To maintain focus and efficiency, the system used multiple task specific agents rather than a single general purpose agent. Each agent operated with a narrow context aligned to its task, keeping reasoning clean and reducing the amount of information passed between steps. This improved reliability, reduced token usage, and helped control runtime costs.
Agents were equipped with a small set of generic tools appropriate to their specific responsibilities. Rather than giving every agent unrestricted access, tools were supplied selectively to limit scope and reduce error. Tool discovery and availability were managed at runtime using MCP, allowing the system to expose only what was needed for each task.
Available tools included web search for locating official sources, navigation and extraction tools for structured website parsing, and document readers capable of handling PDFs and scanned content via OCR. This allowed the system to handle the variety of formats commonly found on company websites without introducing specialised or brittle logic.
Results from each task were progressively consolidated into a shared state, allowing partial findings to inform subsequent steps without waiting for the entire process to complete. The runtime configuration also supported multiple rounds of research, enabling dependent tasks to be triggered automatically once prerequisite information was available.
By keeping the core system small and generic, and pushing behaviour into configuration rather than code, the solution remained easy to extend and adapt. New research objectives, data fields, or insurance use cases could be introduced without expanding the codebase, preserving maintainability while supporting evolving underwriting and broker requirements.
Evaluation
Accuracy and reliability were treated as first class requirements. To measure system performance, I created a representative evaluation dataset of companies with publicly available information that could be independently verified online.
The dataset reflected real world conditions. Much of the relevant financial information was contained in PDF documents, including scanned accounting statements rather than machine readable files. This ensured the system was evaluated against the same constraints it would face in production.
The system was evaluated end to end against this dataset, with outputs compared to known reference values. Performance was measured using accuracy and F1 scores. Accuracy measured how often the system returned the correct result, while the F1 score captured how consistently it produced reliable structured data across different cases, balancing completeness with correctness.
For outputs that were naturally unstructured, such as company summaries, evaluation was performed using large language models as a judge. These models assessed responses against predefined criteria for factual alignment, relevance, and completeness, allowing qualitative outputs to be evaluated.
Together, these evaluation methods made it possible to assess not just whether the system worked, but how dependable it was under realistic conditions. The findings informed system design and runtime configuration, helping refine agent behaviour and tool usage.
The result was a system with performance characteristics appropriate for live business insurance workflows, balancing speed with the level of accuracy required for risk assessment, pricing, and eligibility decisions.
Outcome
The entire process was fully automated. For each request, the system produced a clean, structured JSON response conforming to a predefined schema, making it straightforward to integrate directly into insurance quoting and underwriting systems.
From a business perspective, the output was predictable, machine readable, and immediately usable. Data accuracy and consistency improved, manual research was reduced, and brokers were able to progress through quoting flows with greater confidence in the underlying data.
Delivery
I was responsible for the full system design, architecture, and implementation. The result showed how agentic systems can replace brittle automation with adaptive behaviour, delivering reliable production outcomes while keeping the codebase small, maintainable, and ready to evolve as insurance products and underwriting requirements change.
Further Ideas
While the research configuration was deployed alongside the system in this implementation, the architecture was intentionally designed to support looser coupling. The same configuration could be managed through a content management system and loaded at startup or refreshed at runtime.
This would allow research goals, data fields, and extraction priorities to be adjusted without redeploying the system, enabling faster iteration as underwriting requirements, insurance products, or data needs change. For broker facing platforms, this opens the door to controlled experimentation, product specific configurations, and quicker response to regulatory or market driven change.
This approach reinforces the broader design principle behind the system: keeping core logic stable while allowing behaviour to evolve through configuration rather than code.